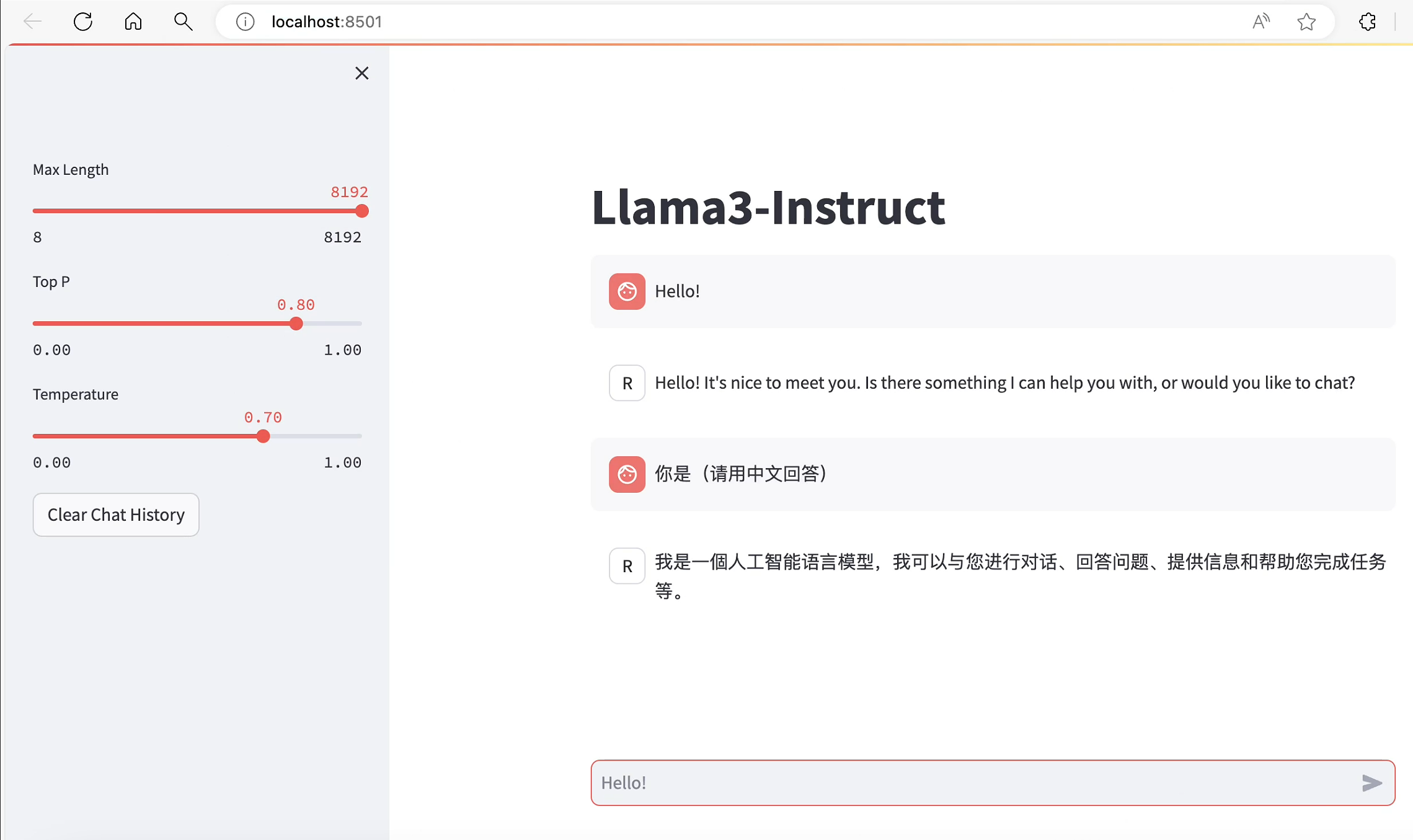
要评估大型语言模型(LLM)的能力,我们可以设计一系列的问题和评估标准,覆盖不同的语言理解和生成任务。下面是一些示例问题及其对应的评估标准:
1. 语言理解能力
问题示例:
- “机器翻译任务中,模型能否准确翻译复杂句子结构?”
- “在阅读理解任务中,模型是否能够准确回答需要深入理解文本的问题?”
评估标准: - 准确率:翻译或回答的正确程度。
- 流利度:生成文本的语法和用词是否自然。
- 一致性:对于相似的问题,模型是否能够给出一致的回答。
2. 逻辑推理能力
问题示例:
- “模型能否解决需要多步推理的问题?”
- “在执行数学推理任务时,模型是否能够正确应用数学规则?”
评估标准: - 推理正确性:推理过程中逻辑的准确性。
- 推理深度:能够处理的多步推理的复杂度。
- 推理效率:完成推理任务所需的时间或计算资源。
3. 知识掌握能力
问题示例:
- “模型是否能够正确回忆起特定的历史事件或科学事实?”
- “在特定领域的问题上,模型能否提供专业的解答?”
评估标准: - 知识广度:模型覆盖的知识领域的范围。
- 知识深度:在特定领域内模型所能提供的详细信息和专业程度。
- 知识更新:模型是否能够处理最新的信息和数据。
4. 生成文本的质量
问题示例:
- “模型能否创作连贯、有吸引力的故事?”
- “在生成新闻报道时,模型是否能够保持客观和准确性?”
评估标准: - 创造性:生成文本的原创性和新颖性。
- 相关性:生成内容与给定主题的相关性。
- 可读性:文本的流畅性和易于理解的程度。
5. 适应性
问题示例:
- “模型在不同语言或方言中是否表现出相同的能力?”
- “在处理不同文体或领域文本时,模型的表现是否稳定?”
评估标准: - 语言适应性:模型在不同语言环境中的表现。
- 风格适应性:模型在处理不同文本风格时的灵活性。
- 领域适应性:模型在陌生或专业领域中的表现。
6. 安全性和伦理性
问题示例:
- “模型是否会生成包含偏见或有害内容的文本?”
- “模型在处理敏感话题时是否能够遵守伦理准则?”
评估标准: - 安全性:模型生成内容的无害性。
- 伦理性:模型是否遵守预设的伦理和社会准则。
- 偏见检测:模型生成内容中是否存在系统性偏见。
在进行评估时,可以通过自动化测试、人工评审、用户反馈等多种方式来综合评定模型的表现。同时,随着技术的发展和社会的变化,评估标准和问题也需要不断更新和调整,以确保评估的有效性和公正性。
Prompt 例子如下:
- 请写一篇关于环保的文章,讨论如何减少塑料污染。
- 根据以下信息,写一个有趣的故事:一个勇敢的小狗,帮助主人找到了丢失的宝藏。
- 请解释一下量子计算机的工作原理。
- 根据以下信息,写一封感谢信:感谢您的朋友在您生病期间照顾您。
- 请描述一下您理想中的假期。
- 根据以下信息,写一个新闻报道:最近的一项研究发现,每天喝三杯咖啡可以降低患心脏病的风险。
- 请解释一下黑洞的形成过程。
- 根据以下信息,写一封建议信:建议您的朋友加入健身房,以保持健康的生活方式。
- 请描述一下您最难忘的一次旅行经历。
- 根据以下信息,写一个辩论稿:辩论是否应该在学校中禁止使用智能手机。
这些Prompt例子可以用于评估模型在生成文本、回答问题、解释概念等方面的能力。根据模型的回答,可以评估其语言理解、逻辑推理、知识掌握、文本生成等能力。